When a disk fails
We've used Varasto so much that we've witnessed disks die and weird disk failures like a disk returning corrupt data, claiming no I/O errors - which Varasto refuses to acknowledge.
All disks eventually fail
You've to prepare for this. We've compiled instructions to help you resolve any issues.
How does Varasto react to error situations?¶
| Situation | Action |
|---|---|
| Read corrupted data | Varasto gives I/O error to user. There is no chance an error is missed even if disk lies and reports OK |
| Write to volume fails | If the volume reports an I/O error, the replica we tried to write won't be recorded in the database |
| Data corrupts on-disk | These generally won't be noticed before trying to read. We support integrity verification scans that detect errors in the background |
TODO
Varasto should auto-unmount (maybe configurable) volumes on encountering errors.
Removing a disk from service¶
When a volume/disk is deemed as about to fail/failed, you should remove it from service. Do these below steps in order:
Take a metadata backup¶
Take a metadata backup so that if you make any mistakes, you can go back. You hopefully have nightly backups, but it's good to take a backup just before this operation so that if you need to resort to the backup, it contains the most recent changes.
Why?
Because we will be making accounting changes in the metadata database. This will be further explained in Mark all volume data lost.
Stop writing new data to the failing disk¶
Remove the volume from any replication policies' New data goes to plan.
UI screenshot
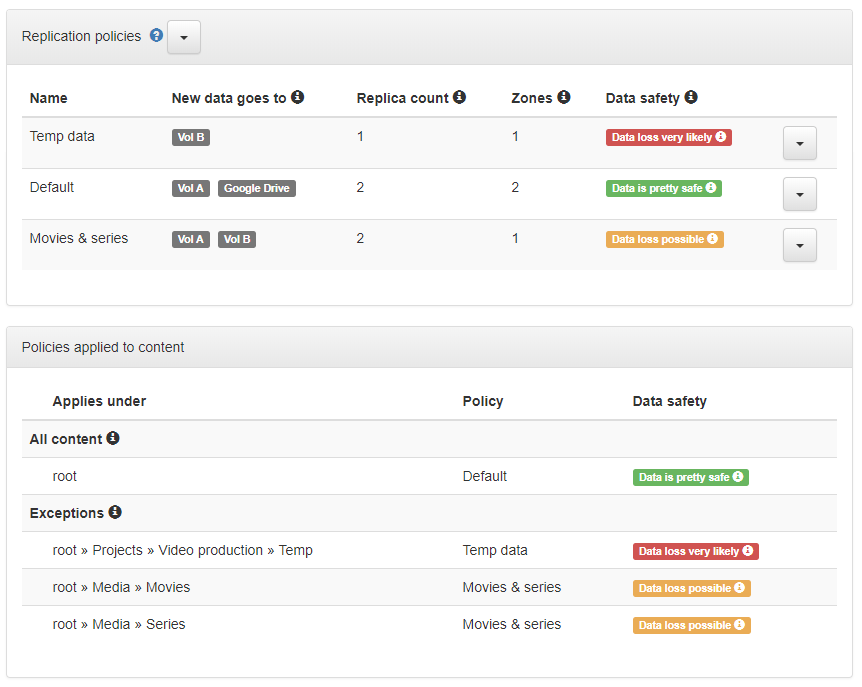
If you want to replicate all data to specific volume¶
This step is optional
You can skip this step, and mark all volume data lost, and the reconciliation step will notice that some data's replication policy now conflicts with the desired replication level. You can then decide (per collection) where the replicas-to-be-satisfied will be placed.
This means that if a big disk broke and you don't have enough space in any single disk to satisfy additional replicas, you can delegate replicas to many volumes so you won't run out of space.
Let's say you had a fully used 4 TB disk that broke. If you have a unused >= 4 TB disk or some other disk with at least 4 TB of free space, you can transfer everything that was on the failed disk to this another volume.
You can use the Migrate data to another volume feature to make sure another volume will
contain the data the volume-to-decommission had before it broke. Migration reads will be
read from healthy replicas, i.e. the feature doesn't mean "transfer data from A to B" -
rather it means "transfer data that was in A, from any healthy replicas, to B".
Mark all volume data lost¶
This operation makes Varasto "forget" which blobs were stored on the volume you're about to decommission - i.e. Varasto will think the volume is empty.
This is done so that replication controller will notice the discrepancy between desired and actual state and start demanding new replicas to make your data safe again.
Tip
For your safety, the command has a Only if redundancy switch so Varasto aborts the
command if it would lose the last redundant replica of any file. This is so that you
have one last chance to decide to try to recover data from a disk if it comes as a
surprise to you that your replication policies didn't spread the data redundantly enough.
Reconcile any lost redundancy¶
Go to Settings > Replication policies > Reconciliation to start a scan that will
notice which data will conflict with the desired replica count and require you to specify
which volume will be used to fulfill the storage needs of the conflicted replica count.
Tip
This scan is done automatically once a day, so it's not a disaster if you forget to do it. But the risk is lower if you scan immediately instead of waiting for the alert to be raised.
Decommission the volume¶
This action checks that volume is safe to decommission and hides the volume from UI in places where you usually only want to see active volumes.
You may now get rid of the disk. Don't worry about secure disposal of the disk, since all the data was encrypted anyway. (provided you used the disk only for Varasto data)